零基礎學 Python3 使用 Selenium 獲取某大型電商網站商品信息
在當前數字化時代,電商網站已成為人們日常購物的主要平臺。對于開發者和數據分析師來說,獲取電商網站的商品信息具有重要的應用價值,例如價格監控、競品分析和市場研究。許多電商網站采用動態加載技術,直接使用傳統方法(如 requests 庫)可能難以獲取完整數據。這時,Selenium 作為一個強大的自動化測試工具,成為解決這一問題的理想選擇。本文將從零基礎出發,指導您如何使用 Python3 和 Selenium 獲取某大型電商網站的商品信息,包括環境搭建、基本操作、數據提取以及常見問題處理。
一、環境準備與安裝
要開始使用 Selenium,首先需要安裝必要的庫和驅動。請確保您已安裝 Python3(推薦 3.6 及以上版本),然后通過 pip 安裝 Selenium 庫:`bash
pip install selenium`
您需要下載與瀏覽器匹配的 WebDriver,例如 ChromeDriver(適用于 Chrome 瀏覽器)或 GeckoDriver(適用于 Firefox)。請從官方網站下載并確保其路徑添加到系統環境變量中,或直接在代碼中指定路徑。
二、基礎 Selenium 操作
Selenium 允許模擬用戶行為,如打開網頁、點擊按鈕和填寫表單。以下是一個簡單的示例,展示如何啟動瀏覽器并訪問一個電商網站:`python
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
啟動 Chrome 瀏覽器(假設 ChromeDriver 在系統路徑中)
driver = webdriver.Chrome()
打開電商網站首頁(此處以示例網站為例,實際使用時請替換為目標網站)
driver.get('https://www.example-mall.com')
等待頁面加載
time.sleep(3)
關閉瀏覽器
driver.quit()`
在運行代碼前,請確保目標網站允許爬蟲行為,并遵守 robots.txt 協議和相關法律法規。
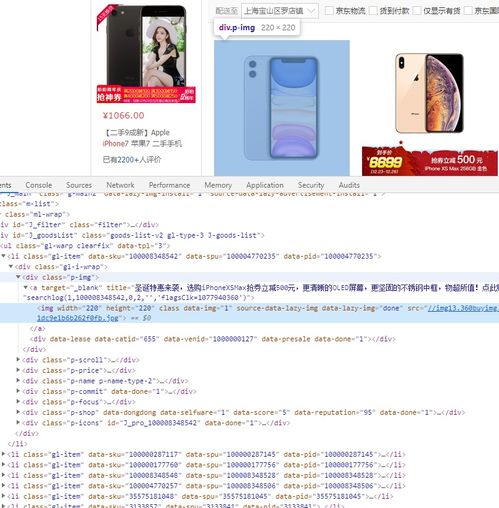
三、定位和提取商品信息
電商網站的商品信息通常包括名稱、價格、評論數和描述等。Selenium 提供了多種元素定位方法,如通過 ID、類名、XPath 或 CSS 選擇器。以下示例演示如何搜索商品并提取信息:`python
# 假設我們已在目標網站,現在搜索關鍵詞“智能手機”
searchbox = driver.findelement(By.ID, 'search-input') # 根據實際元素 ID 調整
searchbox.sendkeys('智能手機')
search_box.submit()
time.sleep(5) # 等待搜索結果加載
提取商品列表中的第一個商品名稱和價格
productname = driver.findelement(By.CLASSNAME, 'product-name').text
productprice = driver.findelement(By.CLASSNAME, 'product-price').text
print(f'商品名稱: {productname}')
print(f'價格: {productprice}')`
對于動態加載的內容(如滾動加載更多商品),您可能需要使用顯式等待(WebDriverWait)來確保元素出現:`python
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
等待商品元素加載,最多等待 10 秒
wait = WebDriverWait(driver, 10)
productelement = wait.until(EC.presenceofelementlocated((By.CLASS_NAME, 'product-item')))`
通過循環遍歷多個元素,您可以批量獲取商品信息,并將其存儲到列表或文件中(如 CSV 或 JSON)。
四、常見問題與優化建議
1. 反爬蟲機制:許多電商網站設有反爬蟲措施,如驗證碼、IP 限制或動態令牌。應對方法包括使用代理 IP、添加延時或使用 Selenium 的隱式等待。請始終尊重網站規則,避免頻繁請求。
2. 性能優化:Selenium 可能較慢,因為它模擬真實瀏覽器。考慮使用 headless 模式(無界面)以提高效率:`python
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)`
3. 數據存儲:將提取的信息保存到文件,便于后續分析。例如,使用 pandas 庫導出為 CSV:`python
import pandas as pd
data = {'名稱': [productname], '價格': [productprice]}
df = pd.DataFrame(data)
df.tocsv('productinfo.csv', index=False)`
五、總結
通過本文,您學習了如何使用 Python3 和 Selenium 從零開始獲取電商網站的商品信息。Selenium 的強大之處在于它能處理 JavaScript 渲染的頁面,但使用時需注意合法性和效率。建議在實際項目中結合其他庫(如 BeautifulSoup 用于解析靜態內容)以優化性能。不斷練習和探索,您將能更熟練地應用這些技能于網絡數據采集任務中。如果您是初學者,可以從簡單網站開始,逐步挑戰更復雜的場景。
如若轉載,請注明出處:http://m.8uun.com/product/708.html
更新時間:2025-12-26 05:01:50